One of the main goals of the InterpretingDL network is to develop a general-purpose framework for applying appropriate analysis and interpretation methods to neural network models of text and speech. We focus on two types of interpretation techniques to evaluate neural models: data-driven and hypothesis-driven methods.
Hypothesis-driven methods test whether specific a priori defined information can be decoded from the internal states of a neural model. For instance, hypothesis-driven methods can be used to answer questions like “Does my translation model encode morphology?”.
Data-driven methods instead do not require a specific hypothesis about what information is encoded, but can consider in a more open way how representations are formed. Data-driven methods are more suitable for open questions such as “What kind of words are the main drivers for a particular translation”.
We aim to advance and integrate both types of interpretation techniques, as we explain below.
Hypothesis-driven methods
A variety of analysis techniques have been proposed in the academic literature for better understanding the representations learned by deep learning models of language. The main families of such methods include diagnostic classifiers (or probing techniques), representational similarity analysis and canonical correlation analysis.
Diagnostic classifiers often use the activations from different layers of a deep learning architecture as input to a prediction model. Success in predicting the target information is taken as evidence that the original model encodes that information in order to perform the task it is optimized for.
Representational Similarity Analysis (RSA) methods are borrowed from neuroscience, and used for correlating data points from two different representation spaces. When applied to deep learning models, layer activations construct one such representation space and are compared to the (structured) linguistic representations of each data item.
Canonical correlation analysis (CCA) techniques allow activations of a deep NLP model to be correlated with those of a parallel predictive model through estimating the strength of association between two canonical variates.
Each of these categories of techniques offer strengths and weaknesses. Our focus is to understand the strengths and weaknesses of each category of techniques, and identify which type of network architecture and analysis task they are best suitable for. Furthermore, we will develop integrated methods that combine the exploratory power of each type of technique1. Finally, we will develop a unified framework for applying different interpretation techniques to each case, depending on the characteristics of the task, the modality of the input and the architecture of the model under investigation.
Data-driven methods
Next to evaluating the representations learned by neural networks, we are also concerned with how and why this information ended up in those representations. In particular, we aim to integrate two techniques that can pin-point which events are responsible for the representation of a model at any particular point in time: layer-wise relevance propagation and contextual decomposition.
Layer-wise Relevance Propagation (LRP) is a method that has worked very well in the domain of vision. It has recently been adapted for the types of models that are typically used for processing text and speech. LRP defines specific gradient-based rules that quantify how ‘relevance’ propagates back through the network. For any particular state of the model, this allows to compute a relevance score for any input that the model received before.
Contextual Decomposition (CD) is a forward method, that uses clever linearisations of the non-linear network dynamics to compute how the information stemming from a particular input or model component propagates forward to the model and contributes to the decisions the model makes later on. Importantly, the generalised version of this method (GCD) also allows to understand how decisions depend on the biases of the model itself, irrespective of the information it receives (see Figure 1).
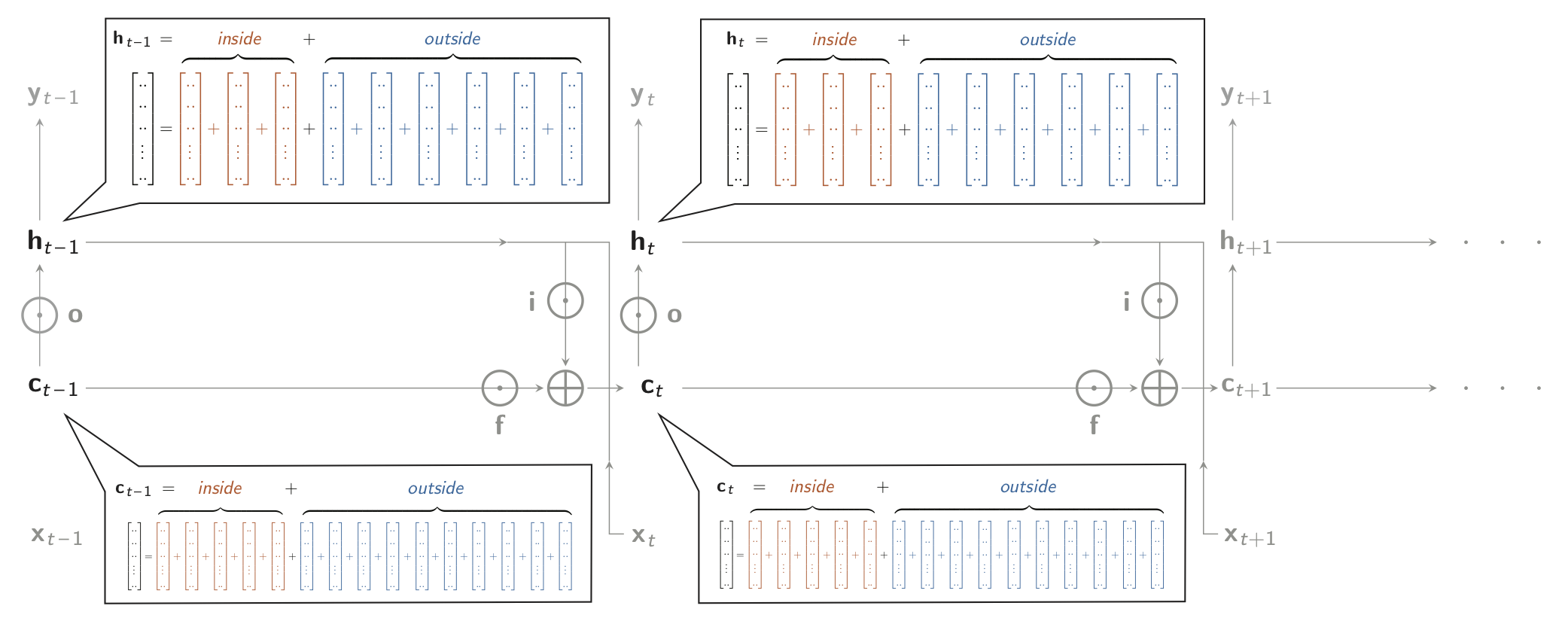
Figure 1. Diagram of an LSTM (unfolded in time), that takes inputs x and produces output y, both changing over time. Shown are the partitionings of the ‘memory cell’ c and the hidden layer h as sums of 15 and 9 terms each, as used in the Contextual Decomposition technique (Murdoch et al., 2018; Jumelet et al., 2019).
Both data-driven methods again have their own advantages and disadvantages. We aim to combine the advantages of both methods to create a best-of-both worlds technique that can show in a computationally efficient way which inputs and model components are responsible for the current model’s decision. We will define and test this technique for several different types of models with different non-linear dynamics and compare the results. Furthermore, we add a specific focus to the influence of the model’s biases, a better understanding of which may play an important role in the development of models that make more fair and predictable decisions.
-
A study combining diagnostic classifiers and RSA-based techniques has been recently published by Chrupała & Alishahi at ACL 2019. ↩